Executive Summary
In our last blog post, we introduced SmartScore, a revolutionary ML-based engine that allows our customers to automatically receive risk scores for cyber incidents generated on our platform. Using advanced machine learning techniques, SmartScore accurately assesses the potential impact of an incident, and by considering a wide range of factors, it provides customers with the information they need to prioritize their incident queue. By using SmartScore, analysts can make informed decisions about resource allocation, increase the efficiency and effectiveness of their incident response processes, and dramatically reduce MTTR (mean-time to resolution).
In this blog, we're highlighting one of the newest features of SmartScore: Explainability. Explainability is powered by SHapley Additive exPlanations (SHAP) and enables end-to-end visibility of the factors that contribute to the overall score of an incident. Explainability provides analysts with insights into the decisions made by Smartscore, so they can effectively respond to incidents and protect their organization.
Houston, We Have a Problem
Security incidents are a growing concern for organizations of all sizes as the frequency and severity of cyberattacks increase. The rise of digital technologies has made it easier for cyber criminals to access sensitive information, causing widespread damage and financial losses. Therefore, it’s becoming increasingly critical for organizations to have the right tools in place to assess and respond to these threats in a timely manner.
However, relying solely on an automatic tool to assign a risk score to each incident may not be enough to meet the needs of today's security analysts. As the volume and complexity of cyber incidents continue to grow, analysts require a deeper understanding of the underlying factors that contribute to the risk score, not just a quick assessment.
Without this understanding and transparency, it can be extremely difficult for analysts to make informed incident response decisions and protect their organizations. Moreover, that level of transparency is crucial in order to communicate efficiently the importance of an incident to stakeholders, and ultimately, staying ahead of stealthy threats that may go unnoticed for a very long period of time.
The Importance of Explainability in AI
Explainability in AI is about making predictions made by artificial intelligence systems more transparent and interpretable. As AI usage increases across industries and applications, organizations must understand the reasoning behind the decisions made by AI systems, particularly in high-stakes scenarios such as healthcare, finance, and security.
Explainability helps organizations identify and address biases in AI models and ensure the decisions made by AI systems are accurate and precise. By providing greater transparency and understanding of how AI systems make decisions, explainability can help organizations build trust and confidence in AI technology and ensure AI is used in responsible and accountable ways.
Given the growing importance of transparency and accountability in AI, at Palo Alto Networks we felt it was crucial to take SmartScore to the next level. As a result, we've added a new explainability section to our engine to provide a deeper understanding of the reasoning behind each incident score. This will let customers see exactly how the score was calculated and what factors contributed to it, providing a more comprehensive view of the incident, its context, and additional insights.
SHAP - Its Qualities and Qualms
SHAP is a powerful tool that has gained significant popularity in recent years due to its ability to provide explanations that are both intuitive and precise. It is used to interpret a wide range of machine learning models, including deep neural networks and random forests. Furthermore, SHAP has been shown to be effective in a variety of industries, including healthcare, finance, and social media analysis. The popularity of SHAP in research is a testament to its usefulness as a tool for understanding and interpreting complex ML models.
SHAP estimates the contribution of each feature to the overall score to provide a global view of the model and to identify which features are driving decisions and which are irrelevant. Additionally, SHAP values can be used to generate local explanations to explain why a particular incident received a specific score.
While SHAP is a powerful tool for model analysis and tuning by data scientists, transforming it into a user-friendly explanation engine is not a trivial task. SHAP’s output is highly technical and connected directly to each individual model. It requires knowledge of the data and the model and cannot be understood by general users. Data Scientists often use SHAP as part of a suite of tools that help them understand the model and its results.
SmartScore Explainability is based on SHAP’s great capabilities and adds an algorithmic layer leveraging SHAP to provide automatic explanations for each incident. The resulting explanations are suitable for all users and don't require any pre-existing knowledge in data science or the specific SmartScore machine learning model.
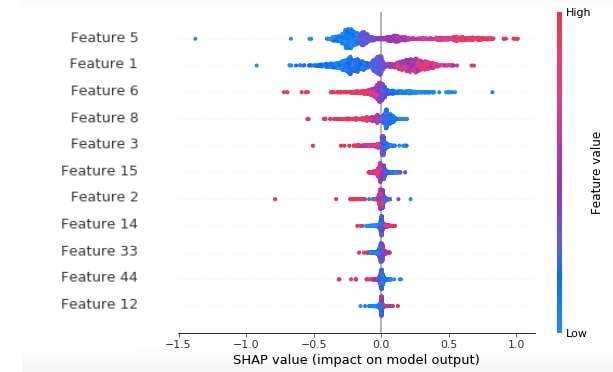
SmartScore Explainability in a Nutshell
The main goal of SmartScore Explainability is to give extra context and insight into both the score and the incident, thus increasing the user’s understanding of the incident and their ability to handle it quickly and efficiently.
The following steps describe the SmartScore Explainability process:
- The algorithm considers the context under which the incident is created. For example: How high is the score? What type of alerts did we see in our incident? What actions were taken by the incident?
- Then we create custom explanations for different scenarios that we are likely to see in incidents.
- Finally, in real time for each specific incident, we combine the algorithmic layer with the SHAP engine to generate an automated explanation that is clear and understandable.
Our system has a wide range of possible explanations that can be generated for each incident. Considering that for each incident the system chooses the best fitting explanation out of the possible explanations, it means that there are thousands of potential explanation combinations for each incident.
We have worked very hard to make sure that these explanations are easy to understand and investigate. Therefore, when our customers read the explanations they immediately know why the score was given and can look into its cause.
Let us review real examples that have been identified by our clients utilizing SmartScore:
SmartScore Explainability in Action
Mimikatz attack via Powershell:
In this incident, Mimikatz was executed from Microsoft PowerShell. The attacker dumped the credentials from the memory in order to escalate their permissions. This technique was successfully blocked by the agent and involved multiple prevention and detection alerts.
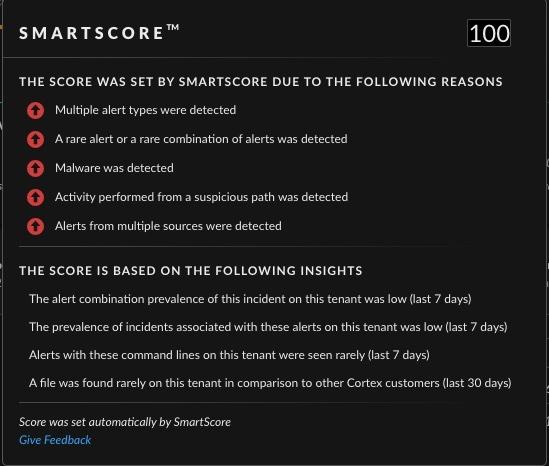
SmartScore Explainability showed that malware was detected in this incident. The malware refers to the Mimikatz executed. In addition, the malware was run from a suspicious path on the machine, and there were multiple alerts from different sources in a unique combination.
Abnormal process execution:
Persistence is a critical part of creating and maintaining a foothold on the user's machine. It enables the attacker to physically or remotely access the system and continue from where it stopped. That was the attacker's intention in this incident.
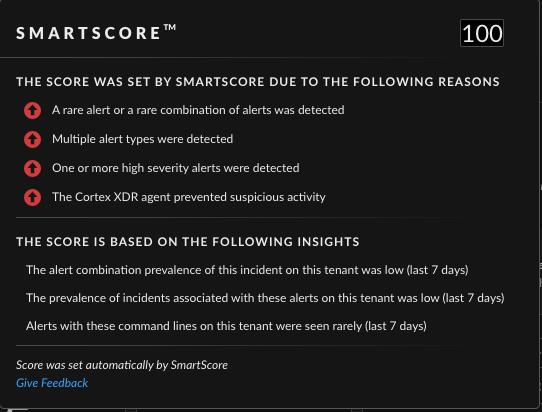
SmartScore Explainability displays multiple reasons for why this activity received a high score: this alert combination is highly unique in the organization, it contains multiple prevention and detection alerts, and it was marked with high severity by the preventions and detections.
Driver installed with high permissions:
Attackers often leverage vulnerable drivers to hide their operations or obtain high privileges. Due to their nature, these types of alerts are quite challenging as they could be legitimate installs or an actual attack.
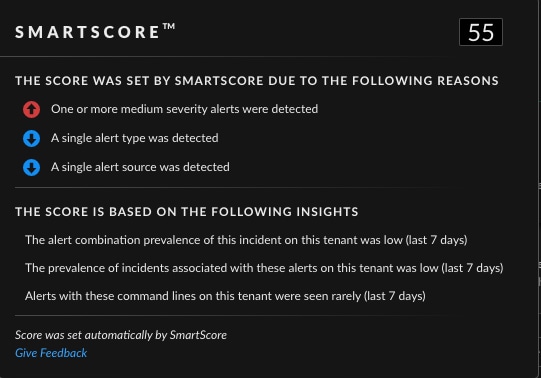
In this instance we can see that the SmartScore is raised to a level that is suspicious, but not extremely high. Although the installed driver is rare for this customer; there was only a single alert. In addition, there is no other suspicious activity related to the alert. This is a great example of an incident that a SOC analyst needs to review and the SmartScore Explainability helps to give context.
Conclusion
SmartScore Explainability provides clear and intuitive explanations of the SmartScore. It helps our customers quickly understand the assigned SmartScore and saves time by reducing the amount of manual analysis required. By providing transparent and interpretable insights, we can increase trust in the score and help SOC analysts better understand their incidents and facilitate them in their goal to keep their company safe.
SmartScore engine was firstly introduced on both XDR 3.4 and XSIAM 1.2, and SmartScore Explainability is available with XDR 3.6 and XSIAM 1.4.
Connect with your account manager to set up a demo to see SmartScore Explainability in action.